Table of Contents
Sesame is an open source Java framework for storing, querying and reasoning with RDF and RDF Schema. It can be used as a database for RDF and RDF Schema, or as a Java library for applications that need to work with RDF internally. For example, suppose you need to read a big RDF file, find the relevant information for your application, and use that information. Sesame provides you with the necessary tools to parse, interpret, query and store all this information, embedded in your own application if you want, or, if you prefer, in a seperate database or even on a remote server. More generally: Sesame provides application developers a toolbox that contains useful hammers, screwdrivers etc. for doing 'Do-It-Yourself' with RDF.
In the next sections, we will take a closer look at Sesame.
The Sesame library consists of a single archive, sesame.jar, which contains Java classes ready for use in your own application. In Chapter 7, The Sesame API, you can find instructions and examples on how to use Sesame in your own code: how to do queries, how to add and remove data, etc.
Sesame can be used as a Server with which client applications (or human users) can communicate over HTTP (see Figure 1.1, “Sesame Server”). Sesame can be deployed as a Java Servlet Application in Apache Tomcat, a webserver that supports Java Servlets and JSP technology.
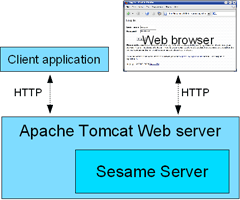
In Chapter 2, Installing Sesame, you will find detailed information on how to install Sesame as a server.
A central concept in the Sesame framework is the repository. A repository is a storage container for RDF. This can simply mean a Java object (or set of Java objects) in memory, or it can mean a relational database. Whatever way of storage is chosen however, it is important to realize that almost every operation in Sesame happens with respect to a repository: when you add RDF data, you add it to a repository. When you do a query, you query a particular repository.
Sesame, as mentioned, supports RDF Schema inferencing. This means that given a set of RDF and/or RDF Schema, Sesame can find the implicit information in the data. Sesame supports this by simply adding all implicit information to the repository as well when data is being added.
It is important to realize that inferencing in Sesame is associated with the type of repository that you use. Sesame supports several different types of repositories (see Chapter 4, Advanced repository configuration for details). Some of these support inferencing, others do not. Whether you want Sesame to do inferencing for you is a choice that depends very much on your application.
In Figure 1.2, “The Sesame architecture” an overview of Sesame's overall architecture is given.
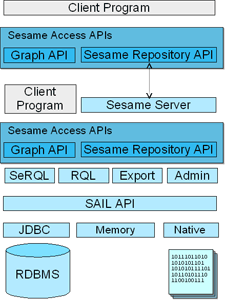
Starting at the bottom, the Storage And Inference Layer, or SAIL API, is an internal Sesame API that abstracts from the storage format used (i.e. whether the data is stored in an RDBMS, in memory, or in files, for example), and provides reasoning support. SAIL implementations can also be stacked on top of each other, to provide functionality such as caching or concurrent access handling. Each Sesame repository has its own SAIL object to represent it.
On top of the SAIL, we find Sesame's functional modules, such as the SeRQL, RQL and RDQL query engines, the admin module, and RDF export. Access to these functional modules is available through Sesame's Access APIs, consisting of two seperate parts: the Repository API and the Graph API. The Repository API provides high-level access to Sesame repositories, such as querying, storing of rdf files, extracting RDF, etc. The Graph API provides more fine-grained support for RDF manipulation, such as adding and removing individual statements, and creation of small RDF models directly from code. The two APIs complement each other in functionality, and are in practice often used together.
The Access APIs provide direct access to Sesame's functional modules, either to a client program (for example, a desktop application that uses Sesame as a library), or to the next component of Sesame's architecture, the Sesame server. This is a component that provides HTTP-based access to Sesame's APIs. Then, on the remote HTTP client side, we again find the access APIs, which can again be used for communicating with Sesame, this time not as a library, but as a server running on a remote location.
While each part of the Sesame code is publicly available and extensible, most developers will be primarily interested in the Access APIs, for communicating with a Sesame RDF model or a Sesame repository from their application. In Chapter 7, The Sesame API, these APIs are described in more detail, through several code examples.