SWI-Prolog HTTP support
Jan Wielemaker
HCS,
University of Amsterdam
The Netherlands
E-mail: wielemak@science.uva.nl
| This article documents the package HTTP, a series of libraries for accessing data on HTTP servers as well as provide HTTP server capabilities from SWI-Prolog. Both server and client are modular libraries. The server can be operated from the Unix inetd super-daemon as well as as a stand-alone server. |
The HTTP (HyperText Transfer Protocol) is the W3C standard protocol for transferring information between a web-client (browser) and a web-server. The protocol is a simple envelope protocol where standard name/value pairs in the header are used to split the stream into messages and communicate about the connection-status. Many languages have client and or server libraries to deal with the HTTP protocol, making it a suitable candidate for general purpose client-server applications. It is the basis of popular agent protocols such as SOAP and FIPA.
In this document we describe a modular infra-structure to access web-servers from SWI-Prolog and turn Prolog into a web-server. The server code is designed to allow the same `body' to be used from an interactive server for debugging or providing services from otherwise interactive applications, run the body from an inetd super-server or as a CGI script behind a generic web-server.
The design of this module is different from the competing XPCE-based
HTTP server located in library(http/httpd.pl), which
intensively uses XPCE functionality to reach its goals. Using XPCE is
not very suitable for CGI or inetd-driven servers due to required X11
connection and much larger footprint.
This work has been carried out under the following projects: GARP, MIA, IBROW and KITS. The following people have pioneered parts of this library and contributed with bug-report and suggestions for improvements: Anjo Anjewierden, Bert Bredeweg, Wouter Jansweijer and Bob Wielinga.
This package provides two packages for building HTTP clients. The
first,
library(http/http_open) is a very lightweight library for
opening a HTTP URL address as a Prolog stream. It can only deal with the
HTTP GET protocol. The second, library(http/http_client) is
a more advanced library dealing with keep-alive, chunked
transfer and a plug-in mechanism providing conversions based on the
MIME content-type.
library(http/http_open)
libraryThe library library(http/http_open) provides a very
simple mechanism to read data from an HTTP server using the HTTP 1.0
protocol and HTTP GET access method. It defines one predicate:
infinite).
_) matches the hyphen
(-). Multiple of these options may be provided to extract
multiple header fields. If the header is not available
AtomValue is unified to the empty atom ('').
Content-Length fields of the reply-header.
User-Agent field of the HTTP
header. Default is SWI-Prolog (http://www.swi-prolog.org).
Here is a simple example:
?- http_open('http://www.swi-prolog.org/news.html', In, []),
copy_stream_data(In, user_output),
close(In).
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<HTML>
<HEAD>
<TITLE>News</TITLE>
</HEAD>
...
|
library(http/http_client)
libraryThe library(http/http_client) library provides more
powerful access to reading HTTP resources, providing keep-alive
connections,
chunked transfer and conversion of the content, such as
breaking down multipart data, parsing HTML, etc. The library
announces itself as providing HTTP/1.1.
close (default) a new connection is created for this
request and closed after the request has completed. If 'Keep-Alive'
the library checks for an open connection on the requested host and port
and re-uses this connection. The connection is left open if the other
party confirms the keep-alive and closed otherwise.
1.1.
User-Agent field of the HTTP
header. Default is SWI-Prolog (http://www.swi-prolog.org).
Remaining options are passed to http_read_data/3.
Name(Value)
pairs to guide the translation of the data. The following options are
supported:
Content-Type as provided by the HTTP reply
header. Intented as a work-around for badly configured servers.
If no to(Target) option is provided the library tries
the registered plug-in conversion filters. If none of these succeed it
tries the built-in content-type handlers or returns the content as an
atom. The builtin content filters are described below. The provided
plug-ins are described in the following sections.
Finally, if all else fails the content is returned as an atom.
library(html_write)
described in section section 3.6.
Content-type equals Type.
application/x-www-form-urlencoded
as produced by browsers issuing a POST request from an HTML form.
ListOfParameter is a list of Name=Value
or
Name(Value).
multipart/form-data as produced
by browsers issuing a POST request from an HTML form using enctype
multipart/form-data. This is a somewhat simplified MIME
multipart/mixed encoding used by browser forms including
file input fields. ListOfData is the same as for the List
alternative described below. Below is an example from the SWI-Prolog
Sesame interface. Repository,
etc. are atoms providing the value, while the last argument provides a
value from a file.
...,
http_post([ protocol(http),
host(Host),
port(Port),
path(ActionPath)
],
form_data([ repository = Repository,
dataFormat = DataFormat,
baseURI = BaseURI,
verifyData = Verify,
data = file(File)
]),
_Reply,
[]),
...,
|
multipart/mixed and packed using mime_pack/3.
See
mime_pack/3 for details on the
argument format.
This plug-in library library(http/http_mime_plugin)
breaks multipart documents that are recognised by the Content-Type:
multipart/form-data or Mime-Version: 1.0 in the
header into a list of Name = Value pairs. This
library deals with data from web-forms using the multipart/form-data
encoding as well as the FIPA
agent-protocol messages.
This plug-in library library(http/http_sgml_plugin)
provides a bridge between the SGML/XML/HTML parser provided by library(sgml)
and the http client library. After loading this hook the following
mime-types are automatically handled by the SGML parser.
library(sgml) using W3C HTML 4.0 DTD, suppressing
and ignoring all HTML syntax errors. Options is passed to
load_structure/3.
library(sgml) using dialect xmlns
(XML + namespaces).
Options is passed to load_structure/3.
In particular,
dialect(xml) may be used to suppress namespace handling.
library(sgml) using dialect sgml. Options
is passed to load_structure/3.
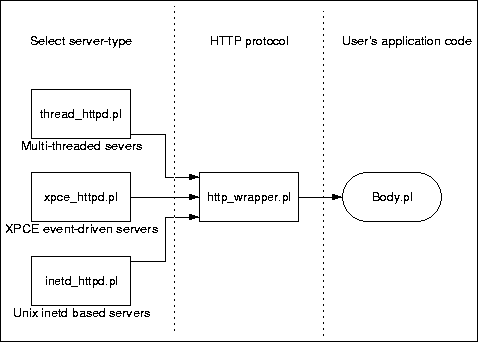
The HTTP server library consists of two parts. The first deals with connection management and has three different implementation depending on the desired type of server. The second implements a generic wrapper for decoding the HTTP request, calling user code to handle the request and encode the answer. This design is summarised in figure 1.
| Figure 1 : Design of the HTTP server |
The functional body of the user's code is independent from the selected server-type, making it easy to switch between the supported server types. Especially the XPCE-based event-driven server is comfortable for debugging but less suitable for production servers. We start the description with how the user must formulate the functionality of the server.
The server-body is the code that handles the request and formulates a
reply. To facilitate all mentioned setups, the body is driven by
http_wrapper/3.
The goal is called with the parsed request (see
section 3.2) as argument and current_output
set to a temporary buffer. Its task is closely related to the task of a
CGI script; it must write a header declaring holding at least the
Content-type field and a body. Here is a simple body
writing the request as an HTML table.
reply(Request) :-
format('Content-type: text/html~n~n', []),
format('<html>~n', []),
format('<table border=1>~n'),
print_request(Request),
format('~n</table>~n'),
format('</html>~n', []).
print_request([]).
print_request([H|T]) :-
H =.. [Name, Value],
format('<tr><td>~w<td>~w~n', [Name, Value]),
print_request(T).
|
Besides returning a page by writing it to the current output stream,
the server goal can raise an exception using throw/1
to generate special pages such as not_found, moved,
etc. The defined exceptions are:
http_reply(Reply,).
http_reply(not_modified,). This exception is
for backward compatibility and can be used by the server to indicate the
referenced resource has not been modified since it was requested last
time.
The body-code (see section 3.1) is driven by
a Request. This request is generated from http_read_request/2
defined in
library(http/http_header).
Name(Value)
elements. It provides a number of predefined elements for the result of
parsing the first line of the request, followed by the additional
request parameters. The predefined fields are:
Host: Host, Host is
unified with the host-name. If Host is of the format <host>:<port>
Host only describes <host> and a field port(Port)
where
Port is an integer is added.
get, put or post.
This field is present if the header has been parsed successfully.
ip(A,B,C,D) containing the IP
address of the contacting host.
host for details.
?,
normally used to transfer data from HTML forms that use the `GET'
protocol. In the URL it consists of a www-form-encoded list of Name=Value
pairs. This is mapped to a list of Prolog Name=Value
terms with decoded names and values. This field is only present if the
location contains a search-specification.
HTTP/Major.Minor
version indicator this element indicate the HTTP version of the peer.
Otherwise this field is not present.
Cookie line, the value of the
cookie is broken down in Name=Value pairs, where
the
Name is the lowercase version of the cookie name as used for
the HTTP fields.
SetCookie line, the cookie field
is broken down into the Name of the cookie, the Value
and a list of Name=Value pairs for additional
options such as expire, path, domain
or secure.
If the first line of the request is tagged with
HTTP/Major.Minor, http_read_request/2
reads all input upto the first blank line. This header consists of
Name:Value fields. Each such field appears as a
term
Name(Value) in the Request, where Name
is canonised for use with Prolog. Canonisation implies that the
Name is converted to lower case and all occurrences of the
- are replaced by _. The value for the
Content-length fields is translated into an integer.
Here is an example:
?- http_read_request(user, X).
|: GET /mydb?class=person HTTP/1.0
|: Host: gollem
|:
X = [ input(user),
method(get),
search([ class = person
]),
path('/mydb'),
http_version(1-0),
host(gollem)
].
|
Where the HTTP GET operation is intended to get a
document, using a path and possibly some additional search
information, the POST operation is intended to hand
potentially large amounts of data to the server for processing.
The Request parameter above contains the term method(post).
The data posted is left on the input stream that is available through
the term input(Stream) from the Request header.
This data can be read using http_read_data/3
from the HTTP client library. Here is a demo implementation simply
returning the parsed pasted data as plain
http://db.cwi.nl/projecten/project.php4?prjnr=129text (assuming pp/1
pretty-prints the data).
reply(Request) :-
member(method(post), Request), !,
http_read_data(Request, Data, []),
format('Content-type: text/plain~n~n', []),
pp(Data).
|
If the POST is initiated from a browser, content-type is generally
either application/x-www-form-urlencoded or
multipart/form-data. The latter is broken down
automatically if the plug-in library(http/http_mime_plugin)
is loaded.
The functionality of the server should be defined in one Prolog file (of course this file is allowed to load other files). Depending on the wanted server setup this `body' is wrapped into a small Prolog file combining the body with the appropriate server interface. There are three supported server-setups:
library(xpce_httpd) for an event-driven serverThis server setup is very suitable for debugging as well as embedded server in simple applications in a fairly controlled environment.
library(thread_httpd) for a multi-threaded
serverThis server is a harder to debug due to the involved threading. It can provide fast communication to multiple clients and can be used for more demanding embedded servers, such as agent platforms.
library(inetd_httpd) for server-per-clientThis server is very hard to debug as the server is not connected to the user environment. It provides a robust implementation for servers that can be started quickly.
All the server interfaces provide http_server(:Goal, +Options)
to create the server. The list of options differ, but the servers share
common options:
call(Goal, Request). This
extension was added to support the FIPA-HTTP protocol, which issues HTTP
POST requests on the server. The server answers these requests with an
empty document before starting processing. The after-option
is used for the processing:
:- http_server(reply, [after(action), ...]).
reply(Request) :-
format('Content-type: text/plain\r\n\r\n').
action(Request) :-
<start agent work on request>
|
The library(http/xpce_httpd.pl) provides the
infrastructure to manage multiple clients with an event-driven
control-structure. This version can be started from an interactive
Prolog session, providing a comfortable infra-structure to debug the
body of your server. It also allows the combination of an (XPCE-based)
GUI with web-technology in one application.
port(?Port) option to specify the port the
server should listen to. If Port is unbound an arbitrary free
port is selected and Port is unified to this port-number. The
only other option provided is the after(:Goal) option.
The file demo_xpce gives a typical example of this
wrapper, assuming demo_body defines the predicate reply/1.
:- use_module(xpce_httpd).
:- use_module(demo_body).
server(Port) :-
http_server(reply, Port, []).
|
The created server opens a server socket at the selected address and waits for incoming connections. On each accepted connection it collects input until an HTTP request is complete. Then it opens an input stream on the collected data and using the output stream directed to the XPCE socket it calls http_wrapper/3. This approach is fundamentally different compared to the other approaches:
The library(http/thread_httpd.pl) provides the
infrastructure to manage multiple clients using a pool of worker-threads.
This realises a popular server design, also seen in SUN JavaBeans and
Microsoft .NET. As a single persistent server process maintains
communication to all clients startup time is not an important issue and
the server can easily maintain state-information for all clients.
In addition to the functionality provided by the other (XPCE and
inetd) servers, the threaded server can also be used to realise an HTTPS
server exploiting the library(ssl) library. See option
ssl(+SSLOptions) below.
port(?Port)
option to specify the port the server should listen to. If Port
is unbound an arbitrary free port is selected and Port is
unified to this port-number. The server consists of a small Prolog
thread accepting new connection on Port and dispatching these
to a pool of workers. Defined Options are:
infinite,
making each worker wait forever for a request to complete. Without a
timeout, a worker may wait forever on an a client that doesn't complete
its request.
https:// protocol. SSL
allows for encrypted communication to avoid others from tapping the wire
as well as improved authentication of client and server. The SSLOptions
option list is passed to ssl_init/3.
The port option of the main option list is forwarded to the SSL layer.
See the library(ssl) library for details.
This can be used to tune the number of workers for performance. Another possible application is to reduce the pool to one worker to facilitate easier debugging.
All modern Unix systems handle a large number of the services they
run through the super-server inetd. This program reads
/etc/inetd.conf and opens server-sockets on all ports
defined in this file. As a request comes in it accepts it and starts the
associated server such that standard I/O refers to the socket. This
approach has several advantages:
The very small generic script for handling inetd based connections is
in inetd_httpd, defining http_server/1:
Here is the example from demo_inetd
#!/usr/bin/pl -t main -q -f
:- use_module(demo_body).
:- use_module(inetd_httpd).
main :-
http_server(reply).
|
With the above file installed in /home/jan/plhttp/demo_inetd,
the following line in /etc/inetd enables the server at port
4001 guarded by tcpwrappers. After modifying inetd, send the
daemon the HUP signal to make it reload its configuration.
For more information, please check inetd.conf(5).
4001 stream tcp nowait nobody /usr/sbin/tcpd /home/jan/plhttp/demo_inetd |
There are rumours that inetd has been ported to Windows.
To be done.
The body is called by the module library(http/http_wrapper.pl).
This module realises the communication between the I/O streams and the
body described in section 3.1. The interface is
realised by http_wrapper/3:
'Keep-alive' if both ends of the connection want to
continue the connection or close if either side wishes to
close the connection. The only option provided is request(-Request),
providing the executed request to the caller.
This predicate reads an HTTP request-header from In,
redirects current output to a memory file and then runs call(Goal,
Request), watching for exceptions and failure. If Goal
executes successfully it generates a complete reply from the created
output. Otherwise it generates an HTTP server error with additional
context information derived from the exception.
The library library(http/http_header) provides
primitives for parsing and composing HTTP headers. Its functionality is
normally hidden by the other parts of the HTTP server and client
libraries. We provide a brief overview of http_reply/3
which can be accessed from the reply body using an exception as explain
in section 3.1.1.
Field(Value). Type
is one of:
library(http/html_write) described in section
3.6.
File(+MimeType, +Path), but do not include a
modification time header.
stream(+Stream, +Len), but the data on Stream
must contain an HTTP header.
library(http/html_write)
libraryProducing output for the web in the form of an HTML document is a requirement for many Prolog programs. Just using format/2 is satisfactory as it leads to poorly readable programs generating poor HTML. This library is based on using DCG rules.
The library(http/html_write) structures the generation
of HTML from a program. It is an extensible library, providing a DCG
framework for generating legal HTML under (Prolog) program control. It
is especially useful for the generation of structured pages (e.g. tables)
from Prolog data structures.
The normal way to use this library is through the DCG html/1. This grammar-rule provides the central translation from a structured term with embedded calls to additional translation rules to a list of atoms that can then be printed using print_html/[1,2].
-->
\List
\Term
\Term but allows for invoking grammar rules in
external packages.
Tag(Content)
Tag(Attributes, Content)Name(Value) or
Name(Value).
-->DOCTYPE declaration. HeadContent are elements to
be placed in the head element and BodyContent
are elements to be placed in the body element.
http://db.cwi.nl/projecten/project.php4?prjnr=129To achieve common
style (background, page header and footer), it is possible to define DCG
rules head/1 and/or body/1.
The page/1 rule checks
for the definition of these DCG rules in the module it is called from as
well as in the user module. If no definition is found, it
creates a head with only the HeadContent (note that the
title is obligatory) and a body with bgcolor
set to white and the provided BodyContent.
Note that further customisation is easily achieved using html/1 directly as page/2 is (besides handling the hooks) defined as:
page(Head, Body) -->
html([ \['<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 4.0//EN">\n'],
html([ head(Head),
body(bgcolor(white), Body)
])
]).
|
-->DOCTYPE and the HTML
element. Contents is used to generate both the head and body
of the page.
-->
html_begin(table)
html_begin(table(border(2), align(center)))
|
This predicate provides an alternative to using the
\Command syntax in the html/1
specification. The following two fragments are the same. The preferred
solution depends on your preferences as well as whether the
specification is generated or entered by the programmer.
table(Rows) -->
html(table([border(1), align(center), width('80%')],
[ \table_header,
\table_rows(Rows)
])).
% or
table(Rows) -->
html_begin(table(border(1), align(center), width('80%'))),
table_header,
table_rows,
html_end(table).
|
-->The html/1 grammar
rules translates a specification into a list of atoms and layout
instructions. Currently the layout instructions are terms of the format nl(N),
requesting at least N newlines. Multiple consequtive nl(1)
terms are combined to an atom containing the maximum of the requested
number of newline characters.
To simplify handing the data to a client or storing it into a file, the following predicates are available from this library:
Content-length
field of an HTTP reply-header.
In some cases it is practical to extend the translations imposed by
html/1. When using XPCE
for example, it is comfortable to be able defining default translation
to HTML for objects. We also used this technique to define translation
rules for the output of the SWI-Prolog
library(sgml) package.
The html/1 rule first calls the multifile ruleset html_write:expand/1. The other predicates contain commonly rules for defining new rules.
-->
--><&>.
--><&>'".
Though not strictly necessary, the library attempts to generate reasonable layout in SGML output. It does this only by inserting newlines before and after tags. It does this on the basis of the multifile predicate html_write:layout/3
-,
requesting the output generator to omit the close-tag altogether or empty,
telling the library that the element has declared empty content. In this
case the close-tag is not emitted either, but in addition html/1
interprets Arg in Tag(Arg) as a list of
attributes rather than the content.
A tag that does not appear in this table is emitted without additional layout. See also print_html/[1,2]. Please consult the library source for examples.
In the following example we will generate a table of Prolog predicates we find from the SWI-Prolog help system based on a keyword. The primary database is defined by the predicate predicate/5 We will make hyperlinks for the predicates pointing to their documentation.
html_apropos(Kwd) :-
findall(Pred, apropos_predicate(Kwd, Pred), Matches),
phrase(apropos_page(Kwd, Matches), Tokens),
print_html(Tokens).
% emit page with title, header and table of matches
apropos_page(Kwd, Matches) -->
page([ title(['Predicates for ', Kwd])
],
[ h2(align(center),
['Predicates for ', Kwd]),
table([ align(center),
border(1),
width('80%')
],
[ tr([ th('Predicate'),
th('Summary')
])
| \apropos_rows(Matches)
])
]).
% emit the rows for the body of the table.
apropos_rows([]) -->
[].
apropos_rows([pred(Name, Arity, Summary)|T]) -->
html([ tr([ td(\predref(Name/Arity)),
td(em(Summary))
])
]),
apropos_rows(T).
% predref(Name/Arity)
%
% Emit Name/Arity as a hyperlink to
%
% /cgi-bin/plman?name=Name&arity=Arity
%
% we must do form-encoding for the name as it may contain illegal
% characters. www_form_encode/2 is defined in library(url).
predref(Name/Arity) -->
{ www_form_encode(Name, Encoded),
sformat(Href, '/cgi-bin/plman?name=~w&arity=~w',
[Encoded, Arity])
},
html(a(href(Href), [Name, /, Arity])).
% Find predicates from a keyword. '$apropos_match' is an internal
% undocumented predicate.
apropos_predicate(Pattern, pred(Name, Arity, Summary)) :-
predicate(Name, Arity, Summary, _, _),
( '$apropos_match'(Pattern, Name)
-> true
; '$apropos_match'(Pattern, Summary)
).
|
library(http/html_write)
libraryThis library is the result of various attempts to reach at a more satisfactory and Prolog-minded way to produce HTML text from a program. We have been using Prolog for the generation of web pages in a number of projects. Just using format/2 never was a real option, generating error-prone HTML from clumsy syntax. We started with a layour on top of format, keeping track of the current nesting and thus always capable of properly closing the environment.
DCG based translation however naturally exploits Prologs term-rewriting primitives. If generation fails for whatever reason it is easy to produce an alternative document (for example holding an error message).
The approach presented in this library has been used in combination
with
library(http/httpd) in three projects: viewing RDF in a
browser, selecting fragments from an analysed document and presenting
parts of the XPCE documentation using a browser. It has proven to be
able to deal with generating pages quickly and comfortably.
In a future version we will probably define a goal_expansion/2
to do compile-time optimisation of the library. Quotation of known text
and invokation of sub-rules using the \RuleSet
and
<Module>:<RuleSet> operators are
costly operations in the analysis that can be done at compile-time.
Writing servers is an inherently dangerous job that should be carried out with some considerations. You have basically started a program on a public terminal and invited strangers to use it. When using the interactive server or inetd based server the server runs under your privileges. Using CGI scripted it runs with the privileges of your web-server. Though it should not be possible to fatally compromise a Unix machine using user privileges, getting unconstrained access to the system is highly undesirable.
Symbolic languages have an additional handicap in their inherent possibilities to modify the running program and dynamically create goals (this also applies to the popular perl and java scripting languages). Here are some guidelines.
/etc/passwd, but also ../../../../../etc/passwd
are tried by experienced hackers to learn about the system they want to
attack. So, expand provided names using absolute_file_name/[2,3]
and verify they are inside a folder reserved for the server. Avoid
symbolic links from this subtree to the outside world. The example below
checks validity of filenames. The first call ensures proper canonisation
of the paths to avoid an mismatch due to symbolic links or other
filesystem ambiguities.
check_file(File) :-
absolute_file_name('/path/to/reserved/area', Reserved),
absolute_file_name(File, Tried),
atom_concat(Reserved, _, Tried).
|
open(pipe(Command), ...), verify the argument once more.
reply(Query) :-
member(search(Args), Query),
member(action=Action, Query),
member(arg=Arg, Query),
call(Action, Arg). % NEVER DO THIS
|
All your attacker has to do is specify Action as shell
and Arg as /bin/sh and he has an uncontrolled
shell!
The current library has been developed and tested in a number of internal and funded projects at the SWI department of the University of Amsterdam. With this release we hope to streamline deployment within these projects as well as let other profit from the possibilities to use Prolog directly as a web-server.
This library is by no means complete and you are free to extend it. Partially or completely lacking are notably session management and authorisation.